Loading...
loading...AnyCores
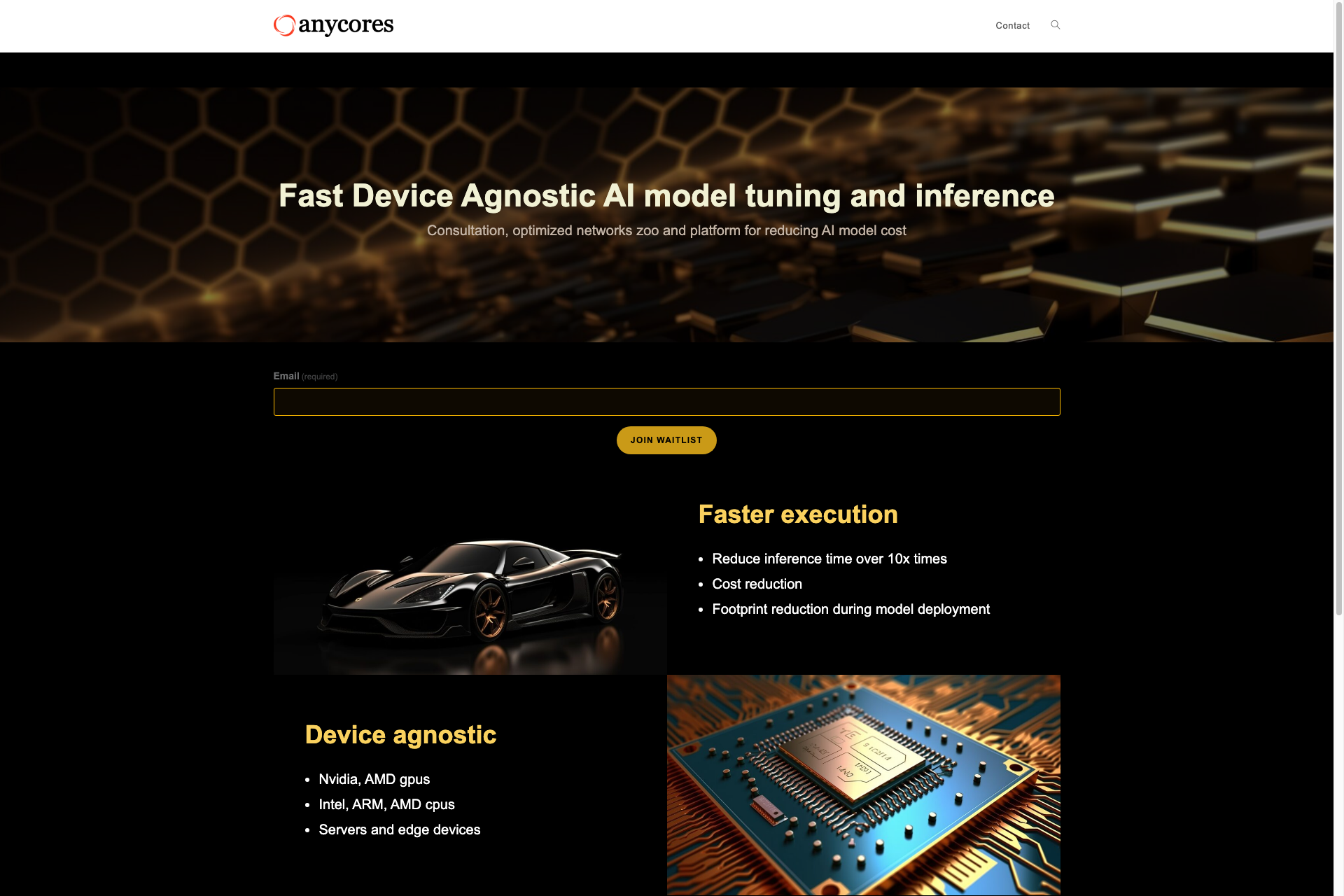
Machine learning models, especially deep neural networks are tend to be computationally heavy. To reduce these costs it is possible to optimize the performance of the networks. A deep learning compiler can provide over 10x acceleration.
Related Products about AnyCores

- Face2face chat with AI Characters. - Conversation driven 3D animation. - Real-time voice chat. - XR integration on the way!

Elevate your Slack experience with: 🚀 Daily standup updates 📊 Employee check-ins 🗳️ Easy polls for better decisions

Stuck on the next line? Let lyric ninja help you find the perfect rhyme. lyric ninja is an AI that helps you with your songwriting. Just give him the lyrics you've already written, and add a few hints and nudges to help with the style, and he'll do the rest.

Effortlessly create stunning videos from text using AI Sora online, whether for realistic or anime scenes.

Build bluetooth apps with AI,encoders which tell people what to type with auto-send and full control over messages with the API

With our Chinese Feng Shui online calculation tool combined with AI intelligent analysis, accurately predict Chinese Feng Shui energy to help optimize your living or business environment, enhancing fortune and well-being.

Join the gaming revolution! Embark on AI-powered adventures with unique plots crafted by designers. More than chatbots – we're a new breed of immersive, interactive fun. Experience how AI and human design come together to create engaging narratives!

Got some unstructured creative thoughts & ideas on the go? Don't worry Audio writer takes care of making it more coherent. Record & keep track of your life's journey, Audio Writer can save you tons of hours by transcribing your voice to text.